
UNIDAD 2 Comunicación en los sistemas operativos distribuidos.
Los sistemas distribuidos están basados en las ideas básicas de transparencia, eficiencia, flexibilidad, escalabilidad y fiabilidad. Sin embargo estos aspectos son en parte contrarios, y por lo tanto los sistemas distribuidos han de cumplir en su diseño el compromiso de que todos los puntos anteriores sean solucionados de manera aceptable.
Llamada a procedimiento remoto (RPC)
En el anterior epígrafe hemos estudiado un modelo de interacción entre los procesos de un sistema distribuido que es el modelo cliente-servidor. Para implementarlo, el sistema dispone de dos llamadas al sistema, send y receive, que las aplicaciones utilizan de forma conveniente. Estas primitivas, a pesar de constituir la base de la construcción de los sistemas distribuidos, pertenecen a un nivel demasiado bajo como para programar de forma eficiente aplicaciones distribuidas.
![]()
![]()
2.1.1. Comunicación con los clientes-Servidor (Socket)
Origen de los socket tuvo lugar en una variante del sistema operativo Unix conocida como BSD Unix. En la universidad de Berkeley, en los inicios del Internet, pronto se hizo evidente que los programadores necesitarían un medio sencillo y eficaz para escribir programas capaces de intercomunicarse entre sí. Esta necesidad dio origen a la primera especificación e implementación de sockets.
Cliente-Servidor es el modelo que actualmente domina el ámbito de comunicación, ya que descentraliza los procesos y los recursos. Es un Sistema donde el cliente es una aplicación, en un equipo, que solicita un determinado servicio y existe un software, en otro equipo, que lo proporciona.
Los servicios pueden ser;
a)Ejecución de un programa. b)Acceso a una Base de Datos. c)Acceso a un dispositivo de hardware.
Solo se requiere un medio físico de comunicación entre las maquinas y dependerá de ala naturaleza de este medio la vialidad del sistema.
Definición de Socket: designa un concepto abstracto por el cual dos programas (posiblemente situados en computadoras distintas) pueden intercambiarse cualquier flujo de datos, generalmente de manera fiable y ordenada.
Los sockets proporcionan una comunicación de dos vías, punto a punto entre dos procesos. Los sockets son muy versátiles y son un componente básico de comunicación entre interprocesos e intersistemas. Un socket es un punto final de comunicación al cual se puede asociar un nombre.
Para lograr tener un socket es necesario que se cumplan ciertos requisitos
1.Que un programa sea capaz de localizar al otro. 2.Que ambos programas sean capaces de intercambiarse información.
Por lo que son necesarios tres recursos que originan el concepto de socket
a)Un protocolo de comunicaciones, que permite el intercambio de octetos.
b)Una dirección del Protocolo de Red (Dirección IP, si se utiliza el Protocolo TCP/IP), que identifica una computadora.
c)Un número de puerto, que identifica a un programa dentro de una computadora. Con un socket se logra implementar una arquitectura cliente-servidor. la comunicación es iniciada por uno de los programas (cliente). Mientras el segundo programa espera a que el otro inicie la comunicación (servidor). Un Socket es un archivo existente en el cliente y en el servidor.
si un socket es un punto final de un puente de comunicaron de dos vías entre dos programas que se comunican a través de la red, ¿Cómo funciona?. Normalmente, un servidor funciona en una computadora específica usando un socket con un número de puerto especifico. El cliente conoce el nombre de la maquina (hostname) o el IP, en la cual el servidor esta funcionando y el numero del puerto con el servidor esta conectado.
Si el cliente lanza una demanda de conexión y el servidor acepta la conexión, este abre un socket en un puerto diferente, para que pueda continuar escuchando en el puerto original nuevas peticiones de conexión, mientras que atiende a las peticiones del cliente conectado. El cliente y el servidor pueden ahora comunicarse escribiendo o leyendo en sus respectivos sockets.
RCP (REMOTE PROCEDURE CALL)
El mecanismo general para las aplicaciones cliente-servidor se proporciona por el paquete Remote Procedure Call (RPC). RPC fue desarrollado por Sun Microsystems y es una colección de herramientas y funciones de biblioteca.
Un servidor RPC consiste en una colección de procedimientos que un cliente puede solicitar por el envío de una petición RPC al servidor junto con los parámetros del procedimiento. El servidor invocará el procedimiento indicado en nombre del cliente, entregando el valor de retorno, si hay alguno. Para ser independiente de la máquina, todos los datos intercambiados entre el cliente y el servidor se convierten al formato External Data Representation (XDR) por el emisor, y son reconvertidos a la representación local por el receptor. RPC confía en sockets estándar UDP y TCP para transportar los datos en formato XDR hacia el host remoto. Sun amablemente a puesto RPC en el dominio público; se describe en una serie de RFCs.
Un servidor RPC ofrece una o más colecciones de procedimientos; cada conjunto se llama un programa y es identificado de forma única por un número de programa.
La llamada remota toma 10 pasos, en el primero de los cuales el programa cliente (o procedimiento) llama al procedimiento stub enlazado en su propio espacio de direcciones. Los parámetros pueden pasarse de la manera usual y hasta aquí el cliente no nota nada inusual en esta llamada ya que es una llamada local normal.
El stub cliente reúne luego los parámetros y los empaqueta en un mensaje. Esta operación se conoce como reunión de argumentos (parameter marshalling). Después que se ha construido el mensaje, se lo pasa a la capa de transporte para su transmisión (paso 2). En un sistema LAN con un servicio sin conexiones, la entidad de transporte probablemente sólo le agrega al mensaje un encabezamiento y lo coloca en la subred sin mayor trabajo (paso 3). En una WAN, la transmisión real puede ser más complicada. Cuando el mensaje llega al servidor, la entidad de transporte lo pasa al stub del servidor (paso 4), que desempaqueta los parámetros. El stub servidor llama luego al procedimiento servidor (paso 5), pasándole los parámetros de manera estándar. El procedimiento servidor no tiene forma de saber que está siendo activado remotamente, debido a que se lo llama desde un procedimiento local que cumple con
todas las reglas estándares. Únicamente el stub sabe que está ocurriendo algo
particular.
Después que ha completado su trabajo, el procedimiento servidor retorna (paso 6) de la misma forma en que retornan otros procedimientos cuando terminan y, desde luego, puede retornar un resultado a un llamador. El stub servidor empaqueta luego el resultado en un mensaje y lo entrega a la interfaz con transporte (paso 7), posiblemente mediante una llamada al sistema, al igual que en el paso 2. Después que la respuesta retorna a la máquina cliente (paso 8), la misma se entrega al stub cliente (paso 9) que desempaqueta las respuestas. Finalmente, el stub cliente retorna a su llamador, el procedimiento cliente y cualquier valor devuelto por el servidor en el paso 6, se entrega al cliente en el paso 10. El propósito de todo el mecanismo de la es darle al cliente (procedimiento cliente) la ilusión de que está haciendo una llamada a un procedimiento local. Dado el éxito de la ilusión, ya que el cliente no puede saber que el servidor es remoto, se dice que el mecanismo es transparente. Sin embargo, una inspección más de cerca revela algunas dificultades en alcanzar la total transparencia.
![]()
![]()
![]()
2.1.3 Comunicación en grupo
La comunicación en grupo tiene que permitir la definición de grupos, así como características propias de los grupos, como la distinción entre grupos abiertos o que permiten el acceso y cerrados que lo limitan, o como la distinción del tipo de jerarquía dentro del grupo. Igualmente, los grupos han de tener operaciones relacionadas con su manejo, como la creación o modificación.
Sincronización
La sincronización en sistemas de un único ordenador no requiere ninguna consideración en el diseño del sistema operativo, ya que existe un reloj único que proporciona de forma regular y precisa el tiempo en cada momento. Sin embargo, los sistemas distribuidos tienen un reloj por cada ordenador del sistema, con lo que es fundamental una coordinaciónentre todos los relojes para mostrar una hora única. Los osciladores de cada ordenador son ligeramente diferentes, y como consecuencia todos los relojes sufren un desfase y deben ser sincronizados continuamente. La sincronización no es trivial, porque se realiza a través de mensajes por la red, cuyo tiempo de envío puede ser variable y depender de muchos factores, como la distancia, la velocidad de transmisión o la propia saturación de la red, etc.
El reloj
La sincronización no tiene por qué ser exacta, y bastará con que sea aproximadamente igual en todos los ordenadores. Hay que tener en cuenta, eso sí, el modo de actualizar la hora de un reloj en particular. Es fundamental no retrasar nunca la hora, aunque el reloj adelante. En vez de eso, hay que ralentizar la actualización del reloj, frenarlo, hasta que alcance la hora aproximadamente. Existen diferentes algoritmos de actualización de la hora, tres de ellos se exponen brevemente a continuación.
Algoritmo de Lamport
Tras el intento de sincronizar todos los relojes, surge la idea de que no es necesario que todos los relojes tengan la misma hora exacta, sino que simplemente mantengan una relación estable de forma que se mantenga la relación de qué suceso ocurrió antes que otro suceso cualquiera.
Este algoritmose encarga exclusivamente de mantener el orden en que se suceden los procesos. En cada mensaje que se envía a otro ordenador se incluye la hora. Si el receptor del mensaje tiene una hora anterior a la indicada en el mensaje, utiliza la hora recibida incrementada en uno para actualizar su propia hora.
Algoritmo de Cristian
Consiste en disponer de un servidor de tiempo, que reciba la hora exacta. El servidor se encarga de enviar a cada ordenador la hora. Cada ordenador de destino sólo tiene que sumarle el tiempo de transporte del mensaje, que se puede calcular de forma aproximada.
Algoritmo de Berkeley
La principal desventaja del algoritmo de Cristian es que todo el sistema depende del servidor de tiempo, lo cual no es aceptable en un sistema distribuido fiable.
El algoritmo de Berkeley usa la hora de todos los ordenadores para elaborar una media, que se reenvía para que cada equipo actualice su propia hora ralentizando el reloj o adoptando la nueva hora, según el caso.
Comunicación en Grupo
Una hipótesis subyacente e intrínseca de RPC es que la comunicación solo es entre dos partes: el cliente y el servidor [25, Tanenbaum].
A veces existen circunstancias en las que la comunicación es entre varios procesos y no solo dos (ver Figura 8.11 [25, Tanenbaum]):
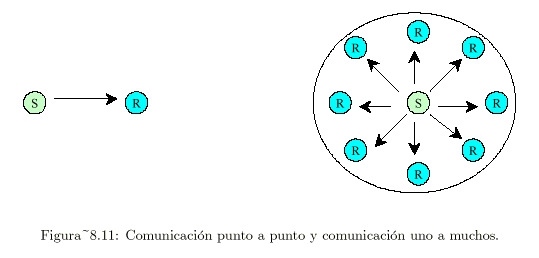
Un grupo es una colección de procesos que actúan juntos en cierto sistema o alguna forma determinada por el usuario.
La propiedad fundamental de todos los grupos es que cuando un mensaje se envía al propio grupo, todos los miembros del grupo lo reciben.
Se trata de una comunicación uno - muchos (un emisor, muchos receptores), que se distingue de la comunicación puntual o punto a punto (un emisor, un receptor).
Los grupos son dinámicos:
La implantación de la comunicación en grupo depende en gran medida del hardware:
Las redes que no soportan multitransmisión operan con transmisión simple:
Otra solución es implantar la comunicación en grupo mediante la transmisión por parte del emisor de paquetes individuales a cada uno de los miembros del grupo:
Aspectos del Diseño de la Comunicación en Grupo
En la comunicación en grupo también se presentan posibilidades tales como [25, Tanenbaum]:
Además existen otras posibilidades que no se dan en la comunicación entre un emisor y un solo receptor.
Grupos Cerrados Vs. Grupos Abiertos
En los grupos cerrados:
En los grupos abiertos:
Los grupos cerrados se utilizan generalmente para el procesamiento paralelo:
Cuando la idea de grupo pretende soportar servidores duplicados:
Grupos de Compañeros Vs. Grupos Jerárquicos
En algunos grupos todos los procesos son iguales:
En otros grupos existe cierto tipo de jerarquía:
Cada tipo de grupo tiene sus ventajas y desventajas:
Un ej. de grupo jerárquico podría ser un programa de ajedrez en paralelo:
Membresía del Grupo
La comunicación en grupo requiere cierto método para:
Una posibilidad es tener un servidor de grupos al cual enviar todas las solicitudes:
Otra posibilidad es la administración distribuida de las membresías a grupos:
Un aspecto problemático se presenta cuando un miembro falla, saliendo por lo tanto del grupo:
Otro aspecto importante es que la entrada y salida al grupo debe sincronizarse con el envío de mensajes:
Un aspecto crítico resulta cuando fallan tantas máquinas que el grupo ya no puede funcionar:
Direccionamiento al Grupo
Los grupos deben poder direccionarse, al igual que los procesos.
Una forma es darle a cada grupo una dirección única, similar a una dirección de proceso.
Si la red soporta multitransmisión:
Si la red no soporta multitransmisión:
Si la red no soporta multitransmisión ni transmisión simple:
Un segundo método de direccionamiento de grupo consiste en pedirle al emisor una lista explícita de todos los destinos:
Un tercer método es el de direccionamiento de predicados (predicate addressing):
Si se fusionan las primitivas puntuales y grupales para receive:
Si es necesario que las respuestas estén asociadas a solicitudes previas:
La única forma de garantizar que cada destino recibe todos sus mensajes es pedirle que envíe de regreso un reconocimiento después de recibir el mensaje:
Una solución puede llegar del algoritmo de Joseph y Birman:
Este algoritmo asegura que todos los procesos sobrevivientes obtendrán el mensaje, independientemente del número de máquinas que fallen o el número de paquetes perdidos.
Ordenamiento de Mensajes
El ordenamiento de los mensajes es un aspecto fundamental en la comunicación en grupo.
Ej.: consideramos 5 máquinas, cada una con un proceso:
El problema es que cuando dos procesos contienden por el acceso a una LAN, el orden de envío de los mensajes no es determinista.
En el ejemplo anterior, los procesos 1 y 3 reciben los mensajes de los procesos 0 y 4 en distinto orden:
Un sistema debe tener una semántica bien definida con respecto al orden de entrega de los mensajes.
La mejor garantía es la entrega inmediata de todos los mensajes, en el orden en que fueron enviados:
Una variante al esquema anterior es el ordenamiento consistente:
Grupos Traslapados
Un proceso puede ser miembro de varios grupos a la vez, pero esto puede generar un nuevo tipo de inconsistencia.
Ej.: supongamos que:
El problema es el siguiente:
Las compuertas pueden afectar la multitransmisión y el hecho requerido por algunas redes de tener un solo paquete en la red en un instante dado.
![]()
![]()
![]()
2.1.4 Tolerancia a fallos
Que el sistema de archivos sea tolerante a fallos implica qué el sistema debe guardar copias del mismo archivo en distintos ordenadores para garantizar la disponibilidad en caso de fallo del servidor original.
Se debe aplicar un algoritmo que nos permita mantener todas las copias actualizadas de forma constante, o un método alternativo que solo nos permita al archivo actualizado como invalidar el resto de copias cuando en cualquiera de ellas se vaya a realizar una operación de escritura.
•
FACTORES QUE AFECTAN LA FIABILIDAD EN LOS SISTEMAS
•
TECNICAS QUE PERMITEN TOLERAR FALLOS EN EL SISTEMA ALGUNOS FALLOS EN EL FUNCIONAMIENTO DE UN SISTEMA PUEDEN ORIGINARSE POR:
•
Especificaciones impropias o con errores.
•
Diseño deficiente e la creación del software y/o el hardware.
•
Deterioros o averías en al hardware.
Interferencias en las comunicaciones (temporales o permanentes).
1. Fallos temporales o transitorios: Desaparecen por si solos al cabo de un
tiempo.
2. Fallos permanentes: Duran hasta que se raparan.
3. Fallos intermitentes: Ocurren solo de vez en cuando.
PREVENCION Y TOLERANCIA A FALLOS
Existen dos formas de aumentar la fiabilidad de un sistema.
1. Prevención de fallos: Se trata de evitar que se implementen sistemas que
pueden introducir fallos.
2. Tolerancia a fallos: Se trata de conseguir que el sistema continué funcionando
correctamente aunque se presenten algunos fallos.
En ambos casos el objetivo es desarrollar sistemas con modos de fallos bien definidos.
HARDWARE:
•
Utilización de componentes fiables.
•
Técnicas rigurosas de ensamblaje de subsistemas.
SOFTWARE:
•
Especificación rigurosa de requisitos.
•
Métodos de diseños comprobados.
•
Lenguajes con abstracción de datos y modularidad.
LA REALIZACION SE BASA EN DOS ETAPAS
1. Evitación de fallos: impedir que se introduzcan fallos durante la construcción
del sistema.
2. Eliminación de fallos: consiste en encontrar y corregir los fallos que se
producen en el sistema una vez construido.
TECNICAS DE ELIMINACION DE FALLOS
Comprobaciones:
Revisiones del diseño.
Verificación de los programas.
Inspección del código.
Pruebas:
Son necesarias pero insuficientes.
Nunca llegan a ser exhaustivas
Solo sirven para mostrar que hay errores pero no que no los hay.
Los errores de especificaciones no se detectan.
LIMITACIONES DE LA PREVENCION DE FALLOS
Los componentes del hardware fallan a pesar de las técnicas de prevención.
La prevención es insuficiente si la frecuencia o la duración de las reparaciones es corta.
No se puede detener el sistema para efectuar reparaciones.
La alternativa es utilizar técnicas de tolerancia a fallos.
TOLERANCIA A FALLOS
Tolerancia completa: el sistema continúa funcionando durante un tiempo sin perder funcionabilidad.
Degradación elegante: El sistema sigue funcionando con una pérdida parcial de funcionabilidad hasta que se repare el fallo.
Parada segura: el sistema se detiene en un estado que asegura la integridad del entorno hasta que se repare el fallo.
![]()
![]()
![]()
2.2 Sincronización en Sistemas Distribuidos
Además de la comunicación, es fundamental la forma en que los procesos [25, Tanenbaum]:
Ejemplos:
Los problemas relativos a las regiones críticas, exclusión mutua y la sincronización:
Otro problema de gran importancia es el tiempo y la forma de medirlo, ya que juega un papel fundamental en algunos modelos de sincronización.
Algoritmos para la Sincronización de Relojes
La sincronización de relojes en un sistemadistribuido consiste en garantizar que los procesosse ejecuten en forma cronológica y a la misma vez respetar el orden de los eventosdentro del sistema. Para lograr esto existen varios métodos o algoritmos que se programan dentro del sistema operativo, entre los cuales tenemos:
Un gran problema en este algoritmo es que el tiempo no puede correr hacia atrás:
Algoritmo de Cristian
Un sistema distribuido basado en el algoritmo de Berkeley no dispone del tiempo coordenado universal (UTC); en lugar de ello, el sistema maneja su propia hora. Para realizar la sincronización del tiempo en el sistema, también existe un servidor de tiempo que, a diferencia del algoritmo de Cristian, se comporta de manera activa. Este servidor realiza un muestreo periódicodel tiempo que poseen algunas de las máquinas del sistema, con lo cual calcula un tiempo promedio, el cual es enviado a todas las máquinas del sistema a fin de sincronizarlo.
Algoritmo de Berkeley
En el algoritmo de Cristian el servidor de tiempo es pasivo.
En el algoritmo de Berkeley el servidor de tiempo:
Es adecuado cuando no se dispone de un receptor UTC.
Varias Fuentes Externas de Tiempo
Los sistemas que requieren una sincronización muy precisa con UTC se pueden equipar con varios receptores de UTC.
Las distintas fuentes de tiempo generaran distintos rangos (intervalos de tiempo) donde “caerán” los respectivos UTC, por lo que es necesaria una sincronización.
Como la transmisión no es instantánea se genera una cierta incertidumbre en el tiempo.
Cuando un procesador obtiene todos los rangos de UTC:
Se deben compensar los retrasos de transmisión y las diferencias de velocidades de los relojes.
Se debe asegurar que el tiempo no corra hacia atrás.
Se debe resincronizar periódicamente desde las fuentes externas de UTC.
Exclusión Mutua
Cuando un proceso debe leer o actualizar ciertas estructuras de datos compartidas [25, Tanenbaum]:
En sistemas monoprocesadores las regiones críticas se protegen con semáforos, monitores y similares.
En sistemas distribuidos la cuestión es más compleja.
Un Algoritmo Centralizado
La forma más directa de lograr la exclusión mutua en un sistema distribuido es simular a la forma en que se lleva a cabo en un sistema monoprocesador.
Se elige un proceso coordinador.
Cuando un proceso desea ingresar a una región crítica:
Si un proceso pide permiso para entrar a una región crítica ya asignada a otro proceso:
Cuando un proceso sale de la región crítica envía un mensaje al coordinador para liberar su acceso exclusivo:
Es un esquema sencillo, justo y con pocos mensajes de control.
La limitante es que el coordinador puede ser un cuello de botella y puede fallar y bloquear a los procesos que esperan una respuesta de habilitación de acceso.
Un Algoritmo Distribuido
El objetivo es no tener un único punto de fallo (el coordinador central).
Un ej. es el algoritmo de Lamport mejorado por Ricart y Agrawala.
Se requiere un orden total de todos los eventos en el sistema para saber cuál ocurrió primero.
Cuando un proceso desea entrar a una región crítica:
Si el receptor no está en la región crítica y no desea entrar a ella, envía de regreso un mensaje o.k. al emisor.
Si el receptor ya está en la región crítica no responde y encola la solicitud.
Si el receptor desea entrar a la región crítica pero aún no lo logró, compara:
Luego de enviar las solicitudes un proceso:
Cuando un proceso sale de la región crítica:
La exclusión mutua queda garantizada sin bloqueo ni inanición.
El número de mensajes necesarios por entrada es “2(n - 1)”, siendo “n” el número total de procesos en el sistema.
No existe un único punto de fallo sino “n”:
Se incrementa la probabilidad de fallo en “n” veces y también el tráfico en la red.
Se puede solucionar el bloqueo si:
Otro problema es que:
Un importante problema adicional es que:
Una mejora consiste en permitir que un proceso entre a una región crítica con el permiso de una mayoría simple de los demás procesos (en vez de todos):
Un Algoritmo de Anillo de Fichas (Token Ring)
Los procesos se organizan por software formando un anillo lógico asignándose a cada proceso una posición en el anillo.
Cada proceso sabe cuál es el siguiente luego de él.
Al inicializar el anillo se le da al proceso “0” una ficha (token) que circula en todo el anillo, que se transfiere del proceso “k” al “k + 1” en mensajes puntuales.
Cuando un proceso obtiene la ficha de su vecino verifica si intenta entrar a una región crítica:
En un instante dado solo un proceso puede estar en una región crítica.
Si la ficha se pierde debe ser regenerada, pero es difícil detectar su perdida:
La falla de un proceso es detectada cuando su vecino intenta sin éxito pasarle la ficha:
Algoritmos de Elección
Son los algoritmos para la elección de un proceso coordinador, iniciador, secuenciador, etc. [25, Tanenbaum].
El objetivo de un algoritmo de elección es garantizar que iniciada una elección ésta concluya con el acuerdo de todos los procesos con respecto a la identidad del nuevo coordinador.
El Algoritmo del Grandulón o de García-Molina
Un proceso “P” inicia una elección cuando observa que el coordinador ya no responde a las solicitudes.
“P” realiza una elección de la siguiente manera:
Un proceso puede recibir en cualquier momento un mensaje elección de otros procesos con un número menor:
En cierto momento todos los procesos han declinado ante uno de ellos, que será el nuevo coordinador, que envía un mensaje coordinador a todos los procesos para anunciarlo.
Si un proceso inactivo se activa realiza una elección:
Un Algoritmo de Anillo
Se supone que los procesos tienen un orden físico o lógico, es decir que cada proceso conoce a su sucesor.
Cuando algún proceso observa que el coordinador no funciona:
Transacciones Atómicas
Las técnicas de sincronización ya vistas son de bajo nivel [25, Tanenbaum]:
Se precisan técnicas de abstracción de mayor nivel que:
Tal abstracción la llamaremos transacción atómica, transacción o acción atómica.
La principal propiedad de la transacción atómica es el “todo o nada”:
El Modelo de Transacción
Supondremos que [25, Tanenbaum]:
![]()
![]()
![]()
2.2.1 Relojes Lógicos
Las computadoras poseen un circuito para el registro del tiempo conocido como dispositivo reloj [25, Tanenbaum].
Es un cronómetro consistente en un cristal de cuarzo de precisión sometido a una tensión eléctrica que:
Para una computadora y un reloj:
Para varias computadoras con sus respectivos relojes:
La diferencia entre los valores del tiempo se llama distorsión del reloj y podría generar fallas en los programas dependientes del tiempo.
Lamport demostró que la sincronización de relojes es posible y presentó un algoritmo para lograrlo.
Lamport señaló que la sincronización de relojes no tiene que ser absoluta:
Para ciertos algoritmos lo que importa es la consistencia interna de los relojes:
Los relojes físicos son relojes que:
Para sincronizar los relojes lógicos, Lamport definió la relación ocurre antes de (happens-before):
Necesitamos una forma de medir el tiempo tal que a cada evento “a”, le podamos asociar un valor del tiempo “C(a)” en el que todos los procesos estén de acuerdo:
El algoritmo de Lamport asigna tiempos a los eventos.
Consideramos tres procesos que se ejecutan en diferentes máquinas, cada una con su propio reloj y velocidad (ver Figura 9.1 [25, Tanenbaum]):
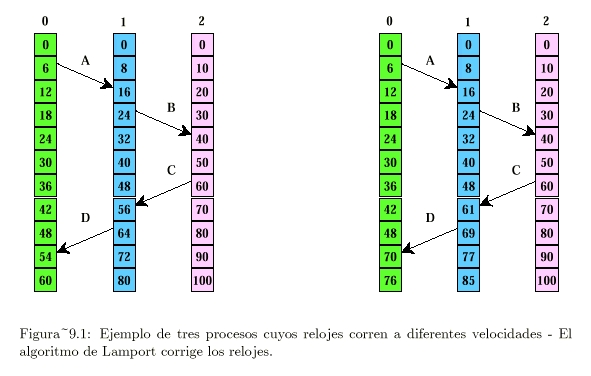
Este algoritmo cumple nuestras necesidades para el tiempo global, si se hace el siguiente agregado:
Con este algoritmo se puede asignar un tiempo a todos los eventos en un sistema distribuido, con las siguientes condiciones:
![]()
![]()
![]()
2.2.2 Relojes Físicos
El algoritmo de Lamport proporciona un orden de eventos sin ambigüedades, pero [25, Tanenbaum]:
La medición del tiempo real con alta precisión no es sencilla.
Desde antiguo el tiempo se ha medido astronómicamente.
Se considera el día solar al intervalo entre dos tránsitos consecutivos del sol, donde el tránsito del sol es el evento en que el sol alcanza su punto aparentemente más alto en el cielo.
El segundo solar se define como 1 / 86.400 de un día solar.
Como el período de rotación de la tierra no es constante, se considera el segundo solar promedio de un gran número de días.
Los físicos definieron al segundo como el tiempo que tarda el átomo de cesio 133 para hacer 9.192.631.770 transiciones:
La Oficina Internacional de la Hora en París (BIH) recibe las indicaciones de cerca de 50 relojes atómicos en el mundo y calcula el tiempo atómico internacional (TAI).
Como consecuencia de que el día solar promedio (DSP) es cada vez mayor, un día TAI es 3 mseg menor que un DSP:
El Instituto Nacional del Tiempo Estándar (NIST) de EE. UU. y de otros países:
Algoritmos con Promedio
Los anteriores son algoritmos centralizados.
Una clase de algoritmos descentralizados divide el tiempo en intervalos de resincronización de longitud fija:
Al inicio de cada intervalo cada máquina transmite el tiempo actual según su reloj.
Debido a la diferente velocidad de los relojes las transmisiones no serán simultáneas.
Luego de que una máquina transmite su hora, inicializa un cronómetro local para reunir las demás transmisiones que lleguen en cierto intervalo “S”.
Cuando recibe todas las transmisiones se ejecuta un algoritmo para calcular una nueva hora para los relojes.
Una variante es promediar los valores de todas las demás máquinas.
Otra variante es descartar los valores extremos antes de promediar (los “m” mayores y los “m” menores).
Una mejora al algoritmo considera la corrección por tiempos de propagación.
![]()
![]()
![]()